Methodology, Architecture and Practice (MAP) for Digital Transformation is a series of blog posts about #DigitalTransformation.
1 Context
At the beginning of October 2018, the
www.africup.tn conference took place in Tunisia. The conference was focused on how to help start-ups. Currently, start-ups are the main “source” of jobs in many countries, especially, on the African continent, because traditional companies don’t create new jobs any more.
The conference has been attended by ministers, investors, start-up leaders and other persons and organizations. During the conference, a law for helping start-ups has been adopted (“Loi Startup Act”
https://www.ilboursa.com/marches/tunisie-la-loi-startup-act-entre-officiellement-en-vigueur_14957).
The general mood at the conference can be described in the following words:
if you can do something right, good and successful for people and countries, there will always be some money for it. Therefore, the conference had a plenary discussion on one of the key problems of Smart Cities of the continent – smart water management.
2 What is Smart City?
Understanding “a city” as any geographically located population (metropolis, town, village, island, etc.), a Smart City is a city that makes the world easier for citizens, business and government by providing solutions to their problems.
These problems are complex because of their multidisciplinary nature as a mixture of economic, social, technological, legal, environmental and ethical aspects. Solutions to such problems must be aligned and balanced against each other to allow Smart Cities reaching their goals in a sustainable (with preserving stability) manner.
3 Complexity of Smart Cities
The urban nature of cites naturally leads to a high level of complexity because of the need to control interacting flows of energy, water, waste, transport, food, etc. Each of these flows needs to maintain a balance, to be capable to handle peak loads, to be prepared for quick elimination of consequences of emergency situations (resilience), etc. The figure below shows some of the relationship between the elements of a city.
Cities are characterized by unpredictable growth, a wide variation in public opinion on priorities, concentration of conflicts and policies.
Each city is unique and all cities have a lot in common.
In the world there are about 4,5 thousand cities with a population of more than 150,000 people.
Construction of a Smart City is not a one-off event but a portfolio of projects with common and evolving purposes.
Making the entire city "smart" cannot be done by a start-up or a mega IT-company (remember General Electric, which tried to make a universal IoT platform alone
https://tbri.com/blog/predix-is-looking-for-a-new-owner/ and failed).
Thus, construction of Smart Cities is a systemic problem that can only be solved systemically with
- involvement of all stakeholders (due to the social orientation of the cities);
- proper coordination (for the construction cost of all "Smart Cities");
- broad cooperation (to use the opportunities within the cities), and
- digital technologies (for ease of information processing and cloning of digital components).
4 Systems approach to Smart Cities
In the year 2017, the IEC (
www.iec.ch) was created a Systems Committee on Smart Cities. This committee considers a Smart City as a sustainable digital system, which consists of several types of systems: socio-technical, information, cyber-physical, computing, etc.
The usual pattern for defining multiple similar systems is to standardize their
reference architecture which will be “adapted” to local conditions by mixing common and specific elements. Based on the reference architecture, various technical committees develop product standards that are used to create various elements. Thanks to the systems approach, such elements form a common and extensible digital platform. At the same time, each Smart City uses its own copy of platform with its own specific elements as shown in figure below.
Knowing that many participants will be involved in construction of Smart Cities, the Systems Committee prepares also a description of the
methodology which is used to develop the reference architecture. At present, the Smart Cities Reference Architecture Methodology (SCRAM) is already in the process of consultation (IEC TS 63188 ED1) with countries which participate in the Systems Committee.
The SCRAM helps different people in similar situations to find similar solutions or suggest innovations. Therefore, the use of this methodology and the availability of the reference architecture will enable a particular city to quickly carry out its architectural works and determine that common solutions can be used and what specific solutions to be developed.
The SCRAM also allows to integrate together a lot of existing works for Smart Cities done by ISO, ITU and many other organisations and consortia.
5 Smart Cities Reference Architecture (SCRA)
The SCRA is built in accordingly with a well-known practice (see ISO / IEC / IEEE 42010): an architecture is described by a consistent set of models that reflects this architecture from different views. Currently, the SCRA uses about 10 views and about 60 models which are defined by the SCRAM. The nomenclature of models and views can be extended because the SCRAM allows to define extra views and extra models as needed. The basic requirement is that all models must be aligned.
It is important that such models describe not only technical aspects, but also reflect social and managerial aspects such as:
- Public discussion (crowdsourcing).
- Public rating (priority and importance). For example, to choose between "important, difficult and long" vs. "maybe relevant, easy and fast”.
- A tree of goals for a specific planning cycle.
- Unified lifecycle models for various elements.
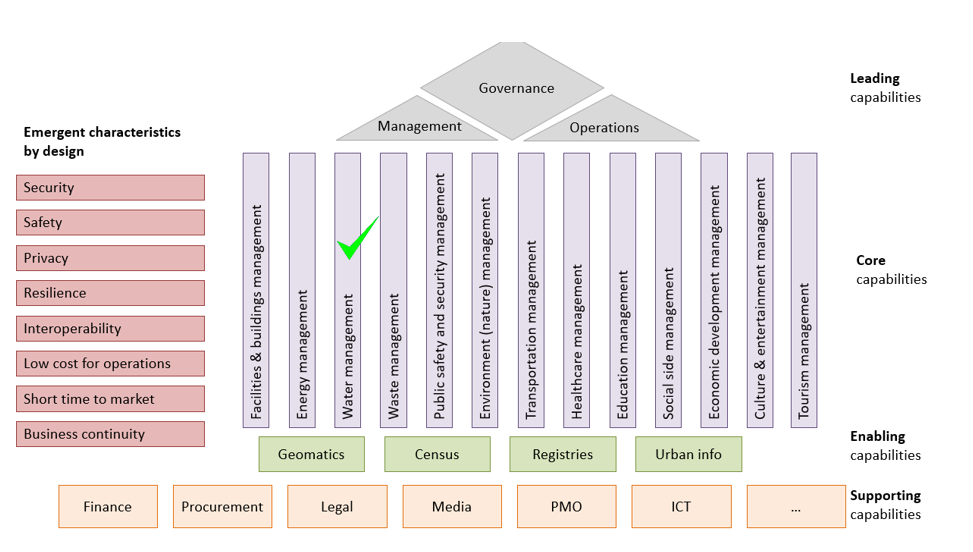
The figure below shows one of the models of the SCRA - the first level capabilities. The green marker indicates the water management area.
The figure below shows another model that describes the SCRA from a different view as a set of components of a digital platform. Again, a green marker indicates the components that are needed to begin implementing water management.
Note that many of such models are not only a description of the SCRA but also components of the digital platform (see
https://improving-bpm-systems.blogspot.com/2018/04/betterarchitecting-with-digital-model. html). Therefore, the SCRA is also part of the reference implementation of Smart Cities.
6 The implementation of Smart Cities
All the "boxes" in the picture above are functional elements and they are still rather complex. Therefore, additional architectural works are required to decompose a complex functional element into a set of simple functional elements that can be implemented by start-ups. As shown in the figure below, the functional elements (in the left part of the figure) are implemented by start-ups as digital modules (in the right part of the figure) to be used within or on top of the digital platform. Processes for decomposition, supervision and assembly are carried out by the Laboratory of Architectural and Technical Governance (see
https://improving-bpm-systems.blogspot.com/2018/09/map/for-digital-transformation.html).
The Laboratory establishes some general rules (including a software factory) and start-ups follow these rules thus forming an ecosystem. Of course, traditional software companies may also participate in such an ecosystem.
7 Is it a new market?
This modular approach to construct multiple Smart Cities can create a new market for digital modules and services. Any digital module can be financed on the basis of equity participation by investors, the government, start-ups and, even, citizens. The acquisition and use of digital modules by some cities may be organized under various compensation agreements, including “pay as you go”. For such a market, it is possible to introduce its own currency.
8 Conclusion
Thus a fully transparent and decentralized scheme is formed for the collective construction of solutions for some wicked problems. To launch this scheme, a "place" (in geographically and broader senses) in which a nexus of four following power-streams will happen is necessary:
- Social (awareness of the situation of a critical mass of society).
- Technological (availability of digital solutions and architectures).
- Implementational (real construction in "live", materialization).
- Financial (transparency who pays, why pays, who benefits) .
Due to the dynamic nature of this nexus there is no need to theorize endlessly about it and his power-streams - the time for talks is over and some practical work must be started to launch this schema and manage the evolution of this nexus.
Smart Cities is the obvious "place" to launch this schema because a city is the beginning of everything and for everything. At the moment, it seems that Tunisia is, potentially, a geopolitical “place” to launch this scheme with an obvious extension to Africa and the Arab world (and, possibly, the Muslim world).
Note that “Smart Cities” is only an example and such a scheme can be applied for “Digital Healthcare”, “Smart Buildings and Dwellings”, “Smart Manufacturing”, “Digital Legislation” and “Digital Government”.
Thanks,
AS