This document is an attempt to outline how BPM (trio: discipline, tools and practices/architecture) can address some concerns of microservices architecture, primarily:
- avoiding “big ball of mud” syndrome (chapter 3)
- recovery from error (chapter 4)
- agility of solutions - will be a separate blogpost, because the primary focus of architecture is not the thing (process, services, etc.) but how the thing changes. (Thanks to Jason Bloomberg ) see http://improving-bpm-systems.blogspot.ch/2014/08/bpm-for-digital-age-shifting.html
- defining microservices (chapter 5)
- making microservices friendly to clouds (chapter 6)
- enhancing information security (chapter 7)
Thus, this document shows a way from monolithic applications to solutions which are based on explicit and executable Coordination Of MicroServices Architecture (COMSA).
The sources about microservices are, primarily,
http://martinfowler.com/articles/microservices.html and
http://www.tigerteam.dk/blog
1
About microservices (as the latest incarnation of #SOA)
The blogpost
http://www.brunton-spall.co.uk/post/2014/05/21/what-is-a-microservice-and-why-does-it-matter/ defines a microservice as following:
- A small problem domain (AS: one function with a couple of screens of code ,often created by just a few people)
- Built and deployed by itself (AS: operationally independent; run on the OS levels; and even ownership independence;– it seems that microservice follows my definition http://www.samarin.biz/terminology/artefacts-important-for-the-bpm-discipline/service )
- Runs in its own process (AS: again, operationally independent, e.g. in its only JVM)
- Integrates via well-known interfaces (AS: interface which is implemented language-independent)
- Owns its own data storage (AS: a microservice may have its own data storage)
2
Implementation techniques for
process-centric solutions
Note, you may want to glance at the chapters 9, 10 and 11 (which provide some information about BPM) before reading this chapter.
2.1 Guiding principles
- Speed of developing automation is the primary factor of agility of a process-centric solution.
- Automation and process template have different speed of changes – keep automation outside the process template.
- Automation may be long-running and resource-consuming.
- Automation may and will fail.
- Failures maybe because of technical (no access to a web service) or business (missing important data) reasons.
- Recovery after failure should be easy.
Automation’s problems (failures, resource consuming) must not undermine the performance of process engine.
2.2 Interpretive languages
Business routines are usually built on existing APIs to access different enterprise systems and repositories. They look like scripting fragments to manipulate some services and libraries. Thus, a combination of interpreted and compiled static programming languages will bring extra flexibility – interpreted language for “fluid” services (business routines) and compiled language for “stable” services (libraries, business objects, data). Examples of such combinations are: Jython and Java, Groovy and Java, etc. In combining them, it is important to use the strong typing to secure interfaces, enjoy introspection, and avoid exotic features.
Example in Jython:
#
# Pending WF
#
# 2001-09-27 AS: Date written
# 2003-04-04 AS: Rewrite
#
# Pre-processing
#
def task_Pre_processing( ) :
print thisW.getTitle(), "Execute task Pre-processing()"
l = thisSession.getResource("/iso/baa/_BO.py")
exec(l)
BO_initBusinessSession (['pmdb', 'twdb'])
ID = thisW.getWorkAttributeAsString(thisWP, "ID")
Language = thisW.getWorkAttributeAsString(thisWP, "Language")
Languages = thisW.getWorkAttributeAsString(thisWP, "Languages")
#
# Find related BO
#
dProjectPmdb = aProjectPmdbHome.findBo ( ID )
if ( not dProjectPmdb.isValid() ) :
_PytErrorAdmin("No standard in the PMDB ID=%s %s" % (ID, dProjectPmdb.getReturnMessage()))
return
pass
# Rename workflow title
if (thisW.getID() != thisSW.getID() ) : # ? subworkflow ?
nameW = thisW.getTitle()
nameSW = thisSW.getTitle()
thisSW.setTitle(nameSW +" for "+nameW)
pass
# Display Project's class
cc = BO_getProjectClass (dProjectPmdb)
thisW.setMasterManager (string.upper(cc[0:1])+string.lower(cc[1:])) ;
pass
#
# Post-processing
#
def task_Post_processing( ) :
print thisW.getTitle(), "Execute task Post-processing()"
pass
2.3 Robot as a generic microservice
Keeping microservices for “business routines” outside the process description allows some quick modifications even within a running process instance. The execution of such microservices can be carried out by a universal service which receives a reference to a text fragment to be interpreted, fetches this text fragment and interpret it. We call this service “robot”; universal robots and specialised robots may co-exist. Robots must be clonable (for scalability, load-balancing and fault-tolerance).
A crash of a robot will not disturb the process engine except that the activity, which caused the crash, will be marked in the process instance as “late” or “overdue”.
2.4 Monitoring
- Ruthless monitoring of all services (including robots, other systems and repositories).
- Not just checking that a port is bound, but asking to do a real work; for example, echo-test.
- Service should be developed in the way to facilitate such a monitoring.
- System should be developed in a way to facilitate such a monitoring.
- Also, robots proactively (before executing automation scripts) must check (via monitoring) the availability of services to be used in a particular automation script.
- It is better to wait a little than recover from an error.
2.5 Explicit versioning of everything
The intrinsic separation between process template and individual process instance in process-centric solutions allows the use the full power of microservice versioning. A lot of variants are possible:
- Process instance may use the “current” version of a particular microservice.
- Process instance may use the particular version of a particular microservice.
- In case of some compliance requirement:
- Since 1st of April all new process instances will use process template v2
- Already running process instances must remain at process template v1
- Some already running process instances will remain at process template v1 (if those instances are close to the completion)
- Some already running process instances may be migrated to process template v2 (if those instances are far from the completion)
Thus everything (process templates, XSD, WSDL, services, namespaces, documents, etc.) must be explicitly versioned and many versions of the “same” should easily co-exist. We also recommend to use the simplest version schema – just sequential numbering: 1, 2, 3, etc.
2.6 Use of other types of coordination in addition to classic process templates
Business rules is another DSL which is very popular in BPM. We recommend to follow the TDM approach ( see http://www.kpiusa.com/ ).
We recommend centralising the treatment of important business events (all external ones and some internal ones) as one service called “dispatch”. The “dispatch” service analyses business events and decides which business process should be initiated. Each process should send to this service an internal business event when the work has been completed (see Figure 1).
Figure 1 “Dispatch” service carries out coordination of processes
See also EPN and BPMN "Explicit event processing agents in BPMN?" at
http://improving-bpm-systems.blogspot.com/2011/01/explicit-event-processing-agents-in.html .
2.7 Pattern PDP (Pre-processing, Doing, Post-processing)
Frequently work is divided into three parts (see Figure 2):
- pre-processing or preparation, e.g. receipt of information from various sources in different formats, or from different repositories, and conversion into a standard presentation;
- doing or processing, i.e. data or information processing in accordance with a standard presentation;
- post-processing or finalisation, e.g. conversion from a standard presentation into a particular presentation.
Figure 2 The PDP pattern
Note, the PDP pattern may be used at the scale of the whole processes.
2.8 Pattern AHA (Automated, Human and Automated)
The AHA pattern is a variant of the PDP pattern aimed at facilitating human work, e.g. collection of data and maybe documents for a human activity (in the same way as a good assistant prepares documents for his/her boss) followed by automation of the follow-up activities. We recommend using this pattern to model all intellectual and verification human activities (see Figure 3).
Figure 3 The AHA pattern
Although in some cases the analysis may define that the pre- or post-processing activity is empty, we recommend that these activities are always inserted – in this way the addition of some automation later will be easy because no changes to the process will be required.
2.9 Pattern ERL (Error Recovery Loop)
Any service invoked within a process may fail. The error must be acted upon in some way, e.g. to re-invoke a service, or to suspend or terminate the process. Figure 4shows a possible approach to treat a service failure – here we ask a human to do something to correct the service and then re-invoke the service. In this diagram we consider that the activity Service returns an error flag which is analysed in the gateway G01.
Figure 4 The ERL pattern (with error return)
If the activity Service raises an exception then the diagram should be as shown in Figure 5.
Figure 5 The ERL pattern (with exception). Note, after “Error recovery” activity the execution continues from the end of respective sub-process, i.e. just before the gateway “G01”.
Activity “Error recovery” may be a human activity for a person who is responsible to carry out necessary corrections actions. Depending on the kind of error, this activity may be assigned to different people.
2.10 Pattern IRIS (Integrity Reached via Idempotency of Services)
To achieve integrity within a process, shall we use the ERL pattern “around” each invocation of a service or not? In general yes, but idempotent services can be grouped (as shown in Figure 6). Idempotency of a service means that it can be invoked many times with the same effect. Any state-less service is idempotent. Some state-full services can have this quality also, e.g. a service to add a new version to a document may ignore the request if the most recent version of this document is exactly the same as the requested one.
The process in Figure 6 may have the following audit trail:
- Activity01 – finished
- Activity02 – failed and raised an exception
- Error Recovery – did something
- Activity01 – finished again thanks to idempotency
- Activity02 – finished
- Activity03 – finished
Figure 6 The IRIS pattern. Note, after “Error recovery” activity the execution continues from the end of respective sub-process, i.e. just before the gateway “G01”.
Note, idempotence (pron.:
/ˌaɪdɨmˈpoʊtəns/ eye-dəm-poh-təns) is the property of certain operations, that can be applied multiple times without changing the result beyond the initial application.
3 Avoiding “distributed big balls of mud”
This problem was mentioned in the blogpost
http://www.codingthearchitecture.com/2014/07/06/distributed_big_balls_of_mud.html with Figure 7 and next quote:
If you can't build a monolith, what makes you think microservices are the answer? If teams find it hard to create a well structured monolith, I don't rate their chances of creating a well structured microservices architecture. As Michael Feathers recently said (in
https://michaelfeathers.silvrback.com/microservices-until-macro-complexity) , "
There's a bit of overhead involved in implementing each microservice. If they ever become as easy to create as classes, people will have a freer hand to create trouble - hulking monoliths at a different scale.". I agree. A world of distributed big balls of mud worries me.
Certainly, I can see a lot of similarities between microservices architecture and process-centric solutions in Figure 8 which is from my book about BPM (
www.samarin.biz/book ), published in the year 2009.
Figure 8 Disassembling monolith into services and assemble them via coordination
The question is how to coordinate separate microservices. The obvious choice is ESB (as shown in Figure 9).
Figure 9 Flow of data
This means that all microservices should be on this picture with potential connectivity everyone to everyone which has the N*(N-1)/2 complexity. Where N is number of microservices resulting in “explosion” of an application. We estimate this number at about 100 per application (or 300 from
http://www.infoq.com/interviews/goldberg-microservices).
Also a couple of issues from ZapThink
http://www.zapthink.com/2013/05/21/cloud-friendly-bpm-the-power-of-hypermedia-oriented-architecture/
- Where to keep the state for this composite service (i.e. ex-application)? If in ESB then this makes ESB too complicated.
- Is ESB cloud-friendly? Just imaging a re-start of the VM with the ESB.
It seems that ESB is necessary but not sufficient. What is missing? We believe that the flow of control is more important than the flow of data (as shown in Figure 10).
Figure 10 Flow of control
In the former, the primary importance is exchange of data. In the latter, the primary importance is the result of working together, but not individual exchanges of data (like in football). Of course, both are necessary, but only ESB is not enough. Considering that more than one coordination techniques may be used by a solution then Figure 11 is more realistic.
Figure 11 Several coordination techniques
The issues (complexity, state and cloud) are answered as following:
- Complexity is much lower because only “business routine” services (which are interacting with the process) are depicted.
- State is discussed in chapter 4.
- Cloud-friendliness is discussed in chapter 6.
Also, some classification of microservices may be added:
- explicit coordination (orchestration, cooperation, biz rules, event processing)
- functional components (like elementary filters in UNIX pipes)
- functional aggregations (e.g. combination of functional components)
- data storages
- data aggregations (i.e. combination data from several data storages)
- human (interactive)
- and some combinations of the previous
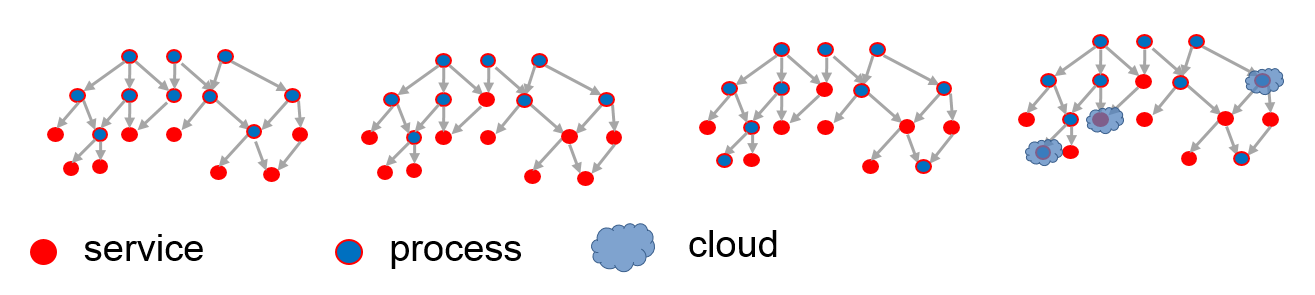
This classification helps to understand which microservices may be provisioned from clouds.
4 Easy recovering from errors (by design)
We all know that the main difference between a monolithic applications and distributed solutions is in the error recovery practices. We need distributed solutions because of the scalability, fault-tolerance and cloud-based provisioning. At the same time, we have to architect the recovery from losing connectivity between nodes and service failure (VM reloading or note failure).
If a subordinated service (relatively to the coordination service) has failed then the coordination service will recover via error recovery loop (see 2.8 and 2.9).
If the coordination service has failed then some of running its subordinated services cannot complete their associated activities; after the restart of the coordination service, those activities will fail by timeout (because each activity has its SLA).
If a resource may change its state without the control of the process then the process must interrogate the state of such a resource before its usage.
Because of processes which provide clear and detailed context, the identification of problems is very quick.
5 Defining microservices
BPM helps to provide context, define, coordinate microservices. It helps to eliminate endless discussions about the necessary “granularity” of the services:
“If we select a top-down style then we will create coarse-grained business-related services, but we are not sure whether such services are implementable or reusable. If we follow a bottom-up style then we will implement too many fine-grained services for which the business value is not obvious.”
Actually, the native flexibility business processes and explicit versioning allow the rapid and painless adaptation of services to increase or decrease their granularity. Any wrong decisions are easily corrected; services are quickly adapted to the required granularity.
6 Explicit allocation of microservices to clouds
See
http://improving-bpm-systems.blogspot.ch/2011/12/enterprise-pattern-cloud-ready.html
7 Enhancing information security
See
http://improving-bpm-systems.blogspot.ch/2014/04/ideas-for-bpmshift-delenda-est-vendor.html and related PPT
http://improving-bpm-systems.blogspot.ch/2013/04/addressing-security-concerns-through-bpm.html
8 Characteristics of a Microservice Architecture annotated
These characteristics are from
http://martinfowler.com/articles/microservices.html
8.1 Componentization via Services
Definition: component is a unit of software that is independently replaceable and upgradeable.
BPM helps to define services.
8.2 Organized around Business Capabilities
Microservices, which, in majority, implement various business artefacts, naturally grow around business capabilities.
8.3 Products not Projects
The three different types of projects appear instead of classic projects:
- Mini-project for developing process-centric solutions (including new microservices)
- Architectural evolution of common components TOGETHER
- Implementation of common components (e.g. BPM suite tool)
Architecture-based agile project management (archibagile) may be useful for mini-projects. ( see
http://improving-bpm-systems.blogspot.ch/2014/06/different-coordination-techniques-in.html ).
8.4 Smart endpoints and dumb pipes
Sure, ESB just a reliable communication mechanism without any business intelligence. Everything is happened in services, even process-centric coordination.
8.5 Decentralized Governance
Sure.
8.6 Decentralized Data Management
Sure again.
8.7 Infrastructure Automation
Yes, also process provides the context for services thus test cases. Process itself is an integration test for its services.
8.8 Design for failure
Sure.
8.9 Evolutionary Design
There are several tempos of design: process, process-specific microservices, common microservices, common operating environment (testing, deployment, monitoring, etc.) and the overall architecture.
Processes make easier to use the power of total versioning. Thus process-specific microservices should mature very quickly.
9 Briefly about Business Process Management (BPM)
BPM (see Figure 12) is a trio: 1) discipline how to better manage an enterprise, 2) COTS and FOSS tools known as BPM suite and 3) an enterprise portfolio of the business processes as well as the practices and tools for governing the design, execution and evolution of this portfolio.
Figure 12 BPM as a trio
The key concept of BPM is business process which is explicitly-defined coordination for guiding the purposeful enactment of business activity flows. In other words, a business process is an agreed plan which is followed each time a defined sequence of activities is carried out; the plan may include some variants and will possibly allow for some unplanned (i.e. unanticipated) changes. (see other BPM-related definitions
http://improving-bpm-systems.blogspot.ch/2014/01/definition-of-bpm-and-related-terms.html ).
The operative word in the above definition is coordination. Although business processes are often associated with only one coordination technique known as template (workflow-like and BPEL-like fixed logic for sequencing activities), there are many coordination techniques (see
http://improving-bpm-systems.blogspot.ch/2014/03/coordination-techniques-in-bpm.html ). The most popular from them are various data-based (also rule-based, decision-based, intelligence-based) and event-based (see EPN -
http://improving-bpm-systems.blogspot.fr/2011/01/explicit-event-processing-agents-in.html ) coordination techniques.
From the behavioural (or dynamic) point of view, various coordination techniques are necessary to provide enough flexibility to realise various variants of BPM usage – see
http://improving-bpm-systems.blogspot.ch/2010/12/illustrations-for-bpm-acm-case.html .
From the structural (or static) point of view, an enterprise can be presented as a system of processes which comprises various coordination constructs of different granularity (process patterns, processes per se, clusters of processes and value-streams) formed via various coordination techniques (see
http://improving-bpm-systems.blogspot.ch/2014/03/enterprise-as-system-of-processes.html ).
For
software architects, it is important to know BPM consider business processes explicit (i.e. formally defined to be understandable by different participants) and executable (conceptually, the process instance executes itself, following the BPM practitioner’s model, but unfolding independent of the BPM practitioner; process instances are performed or enacted, which may include automated aspects).
P.S: Various ways how a company can benefit from a BPM are listed in
http://improving-bpm-systems.blogspot.ch/2014/05/ideas-for-bpmshift-delenda-est-vendor_9.html
10 Structuring executable processes and services
An executable process coordinates the execution of some services. Such a process is expressed in a particular language (i.e. BPMN) and it invokes some services. In Figure 13, the process is in the pool “COOR”, interactive services are in the two pools above it and automated services are in the two pools below it. Note, BPMN is a typical DSL.
Figure 13 Process coordinates some services
This is a classic picture, but how to bring microservices to it?
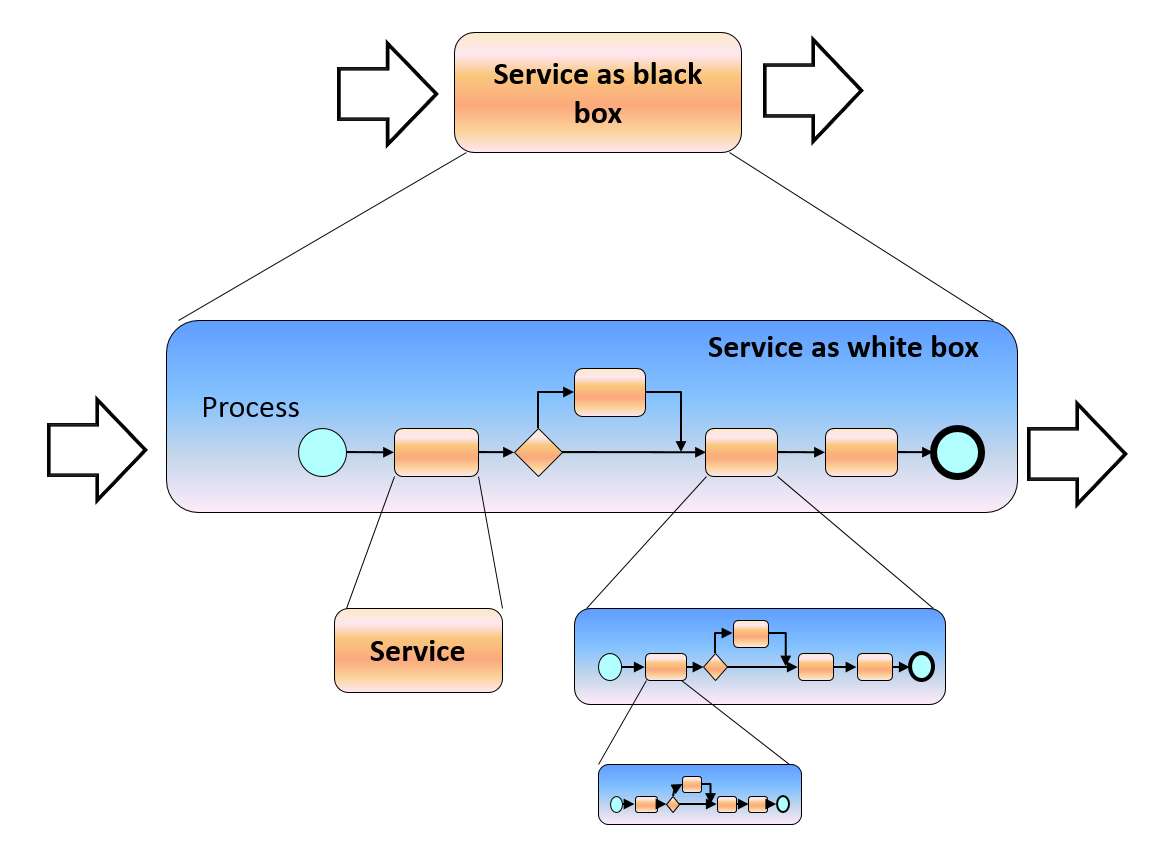
Each enterprise is a complex, dynamic, unique (for each enterprise) and recursive (i.e. like “Russian doll”) relationship (see Figure 14) between services and processes:
- All processes are services
- Some operations of a service can be implemented as a process
- A process includes services in its implementation
Figure 14 Recursive nature of relationship between processes and services
Thus, some “big” services are implemented as explicit and executable processes until only microservices are used.
The relationship does not force to have a “pure” structure, but brings flexibility of converting processes to services and vice-versa as necessary, e.g. to use services provisioned from cloud (as shown in Figure 15).
Figure 15 Structure of process and services
Note that the business process modelling procedure should take care about decomposing a big service into smaller services which are coordinated by the process. Different people in similar situations should find similar services (especially, microservices) although that such a decomposition is creative work. Example of such a modelling procedure is in
http://improving-bpm-systems.blogspot.ch/2013/07/bpm-for-business-analysist-modelling.html .
11 Multi-layered structuring of process-centric solutions
Because a process coordinates various business artefacts , e.g. “Who (roles) is doing What (business objects), When (coordination of activities), Why (business rules), How (business activities) and with Which Results (performance indicators)”, these artefacts can be structured around processes.
This structure arranges different artefacts on separate layers as shown in Figure 16. Each layer is a level of abstraction of the business and addresses some particular concerns.
Figure 16 Multi-level implementation model
More details are available from
http://improving-bpm-systems.blogspot.ch/2011/07/enterprise-patterns-caps.html
Each layer has two roles: it exploits the functionalities of the lower layer, and it serves the higher layer. Each layer has a well-defined interface and its implementation is independent of that of the others. Each layer comprises many services that can be used independently – it is not necessary that all layers be fully implemented at the same time or even be provided in a single project.
Another practical observation is that different layers have lifecycles of different time scales: typical repositories have a 5- to 10-year life-span while the business requires continuous improvement. Because of the implementation independence of the different layers, each layer may evolve at its own pace without being hampered by the others.
Business objects, routines, processes, KPIs, events, rules, audit trails, roles, etc. are the first candidates for microservices which implement particular artefacts.
Thanks,
AS