As we all know, usage of MicroService Architecture (MSA) requires the very comprehensive operational practices and infrastructure. A microservice is a unit-of-functionality (or “class” in the informal IT terminology) within its own unit-of-deployment (or “component” in the informal IT terminology) acting as a unit-of-execution (or “computing process” in the informal IT terminology). Some applications may comprise a few hundred of microservices. This is certainly a serious barrier for exploiting MSA benefits such as easy to update and easy to scale to absorb heavy workloads.
Fortunately, as we know, various performance characteristics (e.g. easy to update, easy to scale) are not spread uniformly within applications. For example, 95% of CPU consumption is located in 5% of program code. Thus, it is not necessary to implement the whole application via microservices.
Let us ask a simple question, if a microservice is, actually, a service then can we use microservices and services together? Yes, and some functionality from platforms or monoliths may be used (via API) as well.
Now, let us reformulate the problem. Let us consider that any application is built from many units-of-functionality which must be deployed and then executed. What is the optimal arrangement of units-of-functionality into units-of-deployment and then units-of-execution? In other words,
- which units-of-functionality have to be implemented as microservices (microservices are agile and good for easy to update, but have some execution and management overhead);
- which units-of-functionality have to be implemented as monoliths (monoliths are not agile and not easy to update, but have no execution and management overhead);
- which units-of-functionality have to be implemented as services (classic services are something in between microservices and monoliths).
Thus, a few recommendations may be formulated.
- Units-of-functionality which are “often” updates must be implemented as microservices (so BizDevOps will be happy).
- Units-of-functionality which require to absorb heavy workloads must be implemented as microservices (so DevOps will be happy).
- Units-of-functionally which are “rarely” updated may be packed in a few units-of-deployment (different “packing” criteria may be used) and each unit-of-deployment has its own computing process (so DevOps will be happy). Another option is dynamic loading of those units-of-functionality.
- Units-of-functionality which are “never” updated may be packed as a monolith or platform, i.e. one unit-of-deployment and one unit-of-execution (so DevOps will be extremely happy).
Applying these recommendations to some phases of the whole application life cycle (conception, development, deployment, production, support, retirement and destruction) the following recommendations may be formulated:
- At the beginning of the application life cycle (concept, i.e. prototyping, and initial development), the majority of the units-of-functionality must be implemented as microservices, because easy to update characteristic is very important (especially for the business people) and, fortunately, performance characteristics are not an issue.
- More close to the end of the development phase, it becomes clear which units-of-functionality have to changed more often than others; so those others may be considered as services and even monoliths or platforms.
- Also, the load tests (during the development and deployment phases) must show which units-of-functionality will require to absorb heavy workloads thus to be implemented as microservices.
- Other criteria may be considered as risk, security, etc.
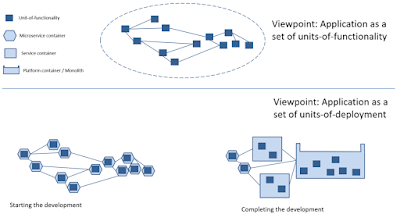
Obviously, that “moving” a unit-functionality from microservice-like implementation to service-like implementation and to platform-like implementation is much easier that “moving” a unit-of-functionality from monolith-like implementation to service-like implementation and to microservice-like implementation.
This confirms the primacy of the “microservices first” approach. This approach, actually, provides support for BizDevOps practices ( see
http://improving-bpm-systems.blogspot.ch/2017/05/beauty-of-microservices-ebanliing.html ). Additionally, this approach enables interesting transformations such as automatic reconfiguration of applications to absorb the heavy workloads by moving temporarily some units-of-functionality from service-like implementation to microservice-like implementation.
Remember from prof. Knuth "Premature optimisation is the root of all evil".
Thanks,
AS

















